
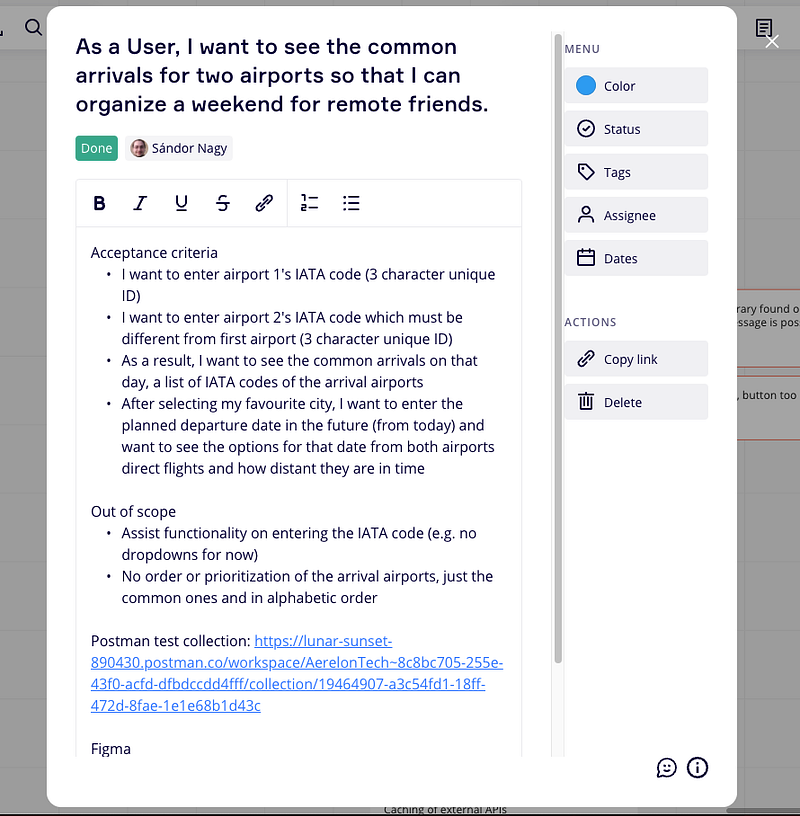
Solution to a user story
Chapter 5 of “Digital Products from zero to hero”
Chapter 5 of “Digital Products from zero to hero”
What is in this chapter:
- in previous chapter we reviewed what is a good user story, how it looks like and how it can describe a valuable increment, now we will solve that described problem from the technical perspective,
- as we are solving for the problem, we need to define the space we are working in, called the architecture of the application, we select the so called tech stack for this project and discuss the different decisions,
- we take a quick thought on how the application should behave holistically, and include not just the user’s perspective.
If you are not familiar with the travel issues I faced with my partner or you are curious how to think about a problem and put it to a simple but effective proof of concept, please check out the first chapter:

I strongly recommend to read the previous posts before this one, as I will use the described user story to build up the solution!
By this point, we have a few great artefacts to work with:
- the Miro board to see the user journey and its context with ideas,
- our Figma prototype showing how the app would work,
- and now the first increment we need to develop to get off the ground.
To solve the increment, to describe the solution I will make for that, we need one more topic to flesh out: the architecture!
As a tech lead and true full-stack engineer, I was always interested in how the system works from end-to-end, meaning how it stores the data, how it processes, transforms and presents it for the frontend, how the same things happen on the frontend until it is seen and interacted by the user, and how the route backwards look. In essence, this is the solution’s architecture, and the role who usually thinks about these problems are filled in by the Solution Architects.
However this is a skill any engineer can work on to develop and you don’t have to be the best backend engineer to be able to understand, just need to build some experience consciously! Let’s do it together and I show how I think about the architecture when I set up any new project from zero!
So from experience as engineers, we know there a few layers to think of:
- data storage,
- backend,
- frontend.
We need to figure out the solution from a couple of perspectives:
- from the end user point of view,
- from our staff or employee’s perspective (who will operate the system),
- from maintenance point of view.
And need to think about the processes and automations we need and how it matches with the development style:
- continuous integration and continuous delivery,
- automated testing, quality assurance,
- number of environments and their purpose.
First and foremost, to collect and be thoughtful about constraints we already have in place:
- I already tested out Python code in Deepnote → backend language should be Python if I want to reduce my efforts.
- I use an iPhone, my partner uses Android → two platforms would increase my efforts to develop twice, so need to solve the frontend with cross-platform technology.
- will be able to work on the project for short timeframes with large breaks in between → need to automate as much as possible!
- the API I plan to use is costly if not controlled → need to have an authentication solution in place to limit the access to me and my partner for now.
- the API I plan to use has two environments already, test and production → I should match at least this much, more could be too much effort or cost.
- I want to jump in as soon as possible and build the app → hosting provider should be a cheap cloud but might want to scale it later without much effort, e.g. AWS free tier is a good start.
So from recent experience, I drafted my architecture vision first:
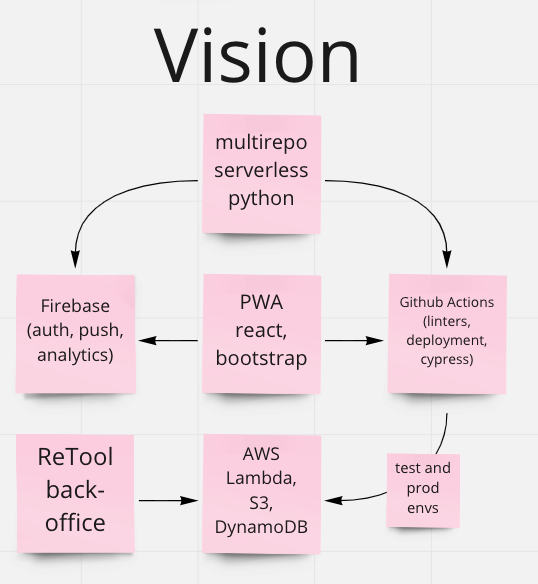
As this topic in itself could be endlessly detailed, why Python and why not the other 200 languages on the market, why GitHub Actions and not CircleCI, etc. let me shortcircuit this part. After a decade in the profession, building up dozens of systems in .NET, Java, Go, Python languages, on-premise and cloud-native solutions, dockerized services, creating automated deployment pipelines in TeamCity, CircleCI, Github Actions, and building applications for Silverlight, WPF, React, Angular and Android platforms gives some perspective.
Now I have some experience which tools work good together and which ones if paired up need more care to be integrated and I have new tech interests where I do want to develop myself next. Over this much time and experience, you will see patterns emerging, a group of tech and tools that work well together simply because their community prefers to build them up this way. Lately I work a lot with reactive systems, message queues and choreography as a central concept in those with large emphasize on scalability and while I think it would be way too much for this small application to start like that, I selected the stack so it will support those changes in the future.
Had limited experience in AWS Lambdas, so I wanted to try them out, checked if they support Python and found great, official sources how to start developing a Flask API, perfect for my needs and I can still separate my code into domains without going too separated and land in function as a service land.
Checked then what data storage is best to fit with Lambdas, looked for PSQL as I have most of my experience in that (after leaving the MSSQL servers behind, those would not fit this ecosystem anyway), however found out due to my research that DynamoDB is pretty good fit for SQL style requests which I am fluent writing, yet it is a document database so better fits my early frequent data structure changes and scalable in future as DynamoDB can emit events when its data changes (great decoupling opportunities!).
Now I need to check how to automate deployment as my goal is to deploy to production immediately when I commit my code without worrying or any manual interactions. Serverless framework was the answer and it can automate the provisioning, the creation of the DynamoDB and proper rights for the services, all the parts I will need to securely deploy and develop my services. And checked for the environments, it supports natively to parameterize the scripts for multiple “stages”, so I can map a dev and a prod stage properly. Checks out.
Now that I covered databases, backend, automated deployment and infrastructure for it, time to look for the frontend technologies: I have experience building teams to deliver with React Native for both iOS and Android at the same time, easy to grab Bootstrap styles for it (and already using this in Figma!) so my first pick will be React Native for the mobile app as I want a native mobile application’s feeling for the user but avoiding the large effort to develop twice on two different platforms. Frontend checked out too. Although, this still requires to build twice to target mobile apps. Still need to use deployment flows with TestFlight and Android Beta release which both are a bit complicated, would be nice if I just deploy static files to a server and I have the frontend. Progressive Web Apps! In short, PWAs are web applications, built with Javascript and they behave like websites when opened from a browser, however if they are opened on a mobile, they can “simulate” an application-like style and behaviour. This would simplify my workflow and setup time so I opted for a React PWA instead of React Native.
Note from future: as this article was in draft for a year, circumstances changed and now you need to be aware of new limitations, at least in EU. As the browser engine monopoly was restricted, Apple dropped support for PWA launches referencing low adoption and large refactoring necessary for the function to work. As of writing this, my app still worked on iOS however this may change sooner or later.
To avoid creating my own authentication system, I checked if there was any popular path between Lambda and React PWA apps and few searches brought up Firebase Auth again, found a good end-to-end tutorial to build a NodeJS API Gateway Lambda Authorizer which I put to my backlog immediately (don’t worry if this was just a word salad for you now, will go into deeper in a later post when I walk you through how to protect the prototype and production too for friends and family!). For now it just important that I know how I will tackle this problem later and it still fits the envisioned architecture. And Firebase has plenty of great tools for free to use during development and I have experience using it so multiple reasons to keep it in the architecture.
Now I want to be able to test both the backend separately and the frontend together with the backend (called end-to-end testing). For backend I use Postman for years now, quick to develop API collections and describe user journeys even (it was so obvious for me that I did not put into my draft above, I use Postman even during proof of concept with Deepnote to figure out API calls and in a future post I will show you how to create simple tests with it with huge impact on any project that uses APIs).
For frontend testing, used Cypress previously with success so I am going to use it again, relatively easy to configure, can run headlessly in GitHub Actions so automated testing now covered for frontend, but how will I host it to share with ourselves wherever we are? I already chose a cloud provider, AWS, so I did not want to increase complexity by choosing a different hosting for my frontend. Simplest solution is an open S3 bucket, as React PWA creates static files at the end which just need to be downloaded by a browser, this does not need an entire server to run on. Simple but effective.
GitHub provides now free private repositories for any organization, you just need to pay for the seats (the people capable to contribute to said organization) above the owner and have free CI/CD automation called GitHub Actions available too.
The last thing I did not cover yet is the ReTool on the draft, which is a no-code/low-code solution to create administrative tools connected to a database and has native connection to DynamoDB, so I figured, if I need to check what is saved into my data tables and if I need to fix or change something, maybe even do some administration, I don’t want to build an entire application from scratch and just use this service. Will go into deeper when I add the city details capability to the application in a later post!
Solution architecture for each backlog item
Wow, lot of text and thoughts and we just barely started, just envisioned how the entire solution will look like. At this stage, I just like draft out the entire tech stack and I will just change it later if something does not fit during building the first increment. During first increment it is still easy to change and with proper approach it will be relatively simple to add new tools and move to new stacks later on too.
But now let’s focus back to our increment. When I have a senior engineer role and I actually deliver a ticket during the project, my way of working goes something like this:
- I gather info in advance: read the user story, check out and try the Figma prototype, read up on relevant system documentations.
- I imagine how I would solve the problem on a higher level, e.g. do I need to create a new microservice? Or can I just modify one? Do I need new data to be stored? How would I map that? and so on
- I write down the solution on a high level into the user story, not like what the code will do line by line, but on the level of “I need to modify X with a new GET call”, “I need a new page which is similar to page Y”, etc.
- If I need to integrate with an existing one or I won’t be the only one working on the user story, I will describe the API schemas too (with JSON examples, a Postman call or collection sometimes)
- When I feel the solution covered all parts to solve for the user, I get offline feedback from the domains that will work on the ticket to solve and from business if I wasn’t the one defining the requirements, I iterate on the story’s solution to incorporate the feedback
This will lead to a bullet point list on what to do and how to solve the ticket so when it is picked up weeks later, we all know what we agreed on. Lots of misunderstandings can be avoided by this, especially by recording the API schemas (events, data schemas too) as this will ensure that the “two sides of the bridge will meet at the center”. Imagine if the building starts, frontend engineer thinks one thing about the API, backend engineer thinks something else and they build at the same time. For sure they won’t have the same API in mind, hence need to work extra at the end to integrate the two sides.
This will usually lead to the simplest solution, frontend won’t start to anything until backend is done and deployed! But this is wasteful and many times backend will learn about the problem when someone actually uses the endpoint so starting early is better. And to avoid the management of half of the story will be done in earlier sprints, as leads to continously open tickets, losing the overview of the project how it progresses and general annoyment for all parties blaming each other why no progress been achieved.
Instead, just agree on the API’s definition before the story is moved into the sprint and any change will be handled as breaking change and not allowed without all parties consent! (Should not happen during a sprint just if we forgot to solve something, otherwise change goes to next sprint always!)
Now that we have the vision and the process how we want to tackle the story, let’s remind ourselves:
So I started with the most fun part for myself: describe the backend API for the frontend in Postman, imagining what would be the data, what order and what I expect as an answer to serve the customer and put it into the collection with examples that are easy to understand and represents the same case I had earlier (the Budapest-Zurich-Bucharest travel).
TODO: screenshot of Postman calls
Now I need to create a new Lambda, let’s name it flights, and implement the aforementioned endpoints.
I need to move the code from Deepnote, integrate with Amadeus API (configuration for API keys) and return the flights in the new data structure.
I need to create a basic React PWA:
- one screen with two input fields and on button call into the deployed API
- second screen to present the list of cities that came back and make them clickable
- when clicked on a city, move to new page and ask for date of departure, when departure date selected (using a date selector in the future) load the flights from both cities,
- but to pair the flights, sounds like a presentation issue and not a backend logic issue, so I could later combine even a third city or different journeys without modifying the backend
- so call the flights endpoint twice, knowing the two start cities and the selected destination, when returned, combine them (I need to rewrite the Python code into Javascript)
- and when returned and paired up, present the pairs in a basic readable manner
- and I need some progress bars on the pages until the API responds (I call external service and can not be sure how fast it returns, milliseconds, seconds or longer)
A different example on how a story looks like in documentation with its proposed solution, and additionally when the solution is ultimately scrapped for a simpler approach:

Refinements, groomings
When working in teams or squads, the next step after the solution is defined is to bring the team together, go over it (after everyone prepared by reading the ticket in 10 minutes on their own!) together and do an estimation. On how to estimate best way, I would not go deep here and it deserves its own post, in short we do a story point estimation, only complexity, effort and risks, never time based! And compare it with previous ethalon stories to see just a weighted numbers for all of them.
There are two reason to do the estimation:
- it brings out misunderstandings, if people wildly disagree how big the ticket is, we discuss it further as there are an unknown risk we need to solve or someone understood differently or other mistakes were done (this is not a blame game! This is for us to have a sanity check on our communication and understanding, especially in multi-national teams, everyone is fully supported and encouraged to state their disagreements so we can together develop our understanding of the problem and the solution!)
- and we can see how much we are able to realistically deliver in one sprint (after a few sprints if you look back on the burn down chart it is visible and can be a good base to ideate how can we evolve further or to detect slow downs later on, again, not a tool for blame or punishment, only for a minor indication if there might be something wrong but does not simply state that we need to deliver more in the next sprint as that will just inflate the numbers and hide the root cause!)
I never take any story as ready for development until this estimation is done and it is always risky to bring in such unestimated stories into sprints. As sprints have fixed scope, unestimated stories just present a surefire way to have some scope creep under your hand!
Tech spikes, PoCs
We talked about in earlier post that not everything can be in a user story. E.g. when I will build the automated pipeline, it is a bit forced to state “As a User, I want to have automated deployments of the application so that I get the best quality after every change”. This would be better as a tech spike and those are still benefiting from describing the tech solution, however we do estimate differently.
In this case, we are better of using time-boxing to estimate, e.g. I can start with: “I can build the GitHub Actions pipeline for a single lambda in 8 hours.” And use the 8 hours mark as a decision point. If I finish earlier, great, have more time to do something else! If I don’t, let’s discuss how important this ticket is. What we learned so far during the 8 hours? How much would it take to finish the task or how to modify, break down, approach differently, etc question can be stated. And make an investor-mindset decision, just what you invest is not money (not directly anyways) but your time.
For the authentication piece I estimated 4 hours for myself but knew I have some risks, like I never solved this exact problem before, just very similar ones. Later it turned out, I spent 16 hours to fix two different bugs and to integrate to the frontend took the most effort. But as I always compared to an unsecured application that could leak out and the underlying costly API would be called without control, the potential loss of money worth the increased amount of effort.
What was the most important is that I was conscious about the decision and the costs compared to the invested time and I wasn’t flying blind.
Epilogue
Now we know what technologies we will use to build the app, we are fairly confident in the solution, it seems it covers all parts and thought through to now just sit down, and write code purposefully!
In next chapter, I will build the backend of the new increment from scratch and test locally!
Insights
- First envision or figure out the architecture, the selected technological stack and tools you will have at your disposal to develop the application!
- Understand and research the requirements, draft out how would you solve it that considers all layers/components of the architecture and provides the valuable increment for the user!
- If working within teams/squads, estimate together so you can root out misunderstandings and have confidence that you thought of everything to the best of your ability!
- Tech spikes (even sometimes bugs) benefit from having a solution drafted out but do time-boxing instead of estimations!